SegGen: Supercharging Segmentation Models
with Text2Mask and Mask2Img Synthesis

Abstract
We propose SegGen, a highly-effective training data generation method for image segmentation, which pushes the performance limits of state-of-the-art segmentation models to a significant extent. SegGen designs and integrates two data generation strategies: MaskSyn and ImgSyn. (i) MaskSyn synthesizes new mask-image pairs via our proposed text-to-mask generation model and mask-to-image generation model, greatly improving the diversity in segmentation masks for model supervision; (ii) ImgSyn synthesizes new images based on existing masks using the mask-to-image generation model, strongly improving image diversity for model inputs.
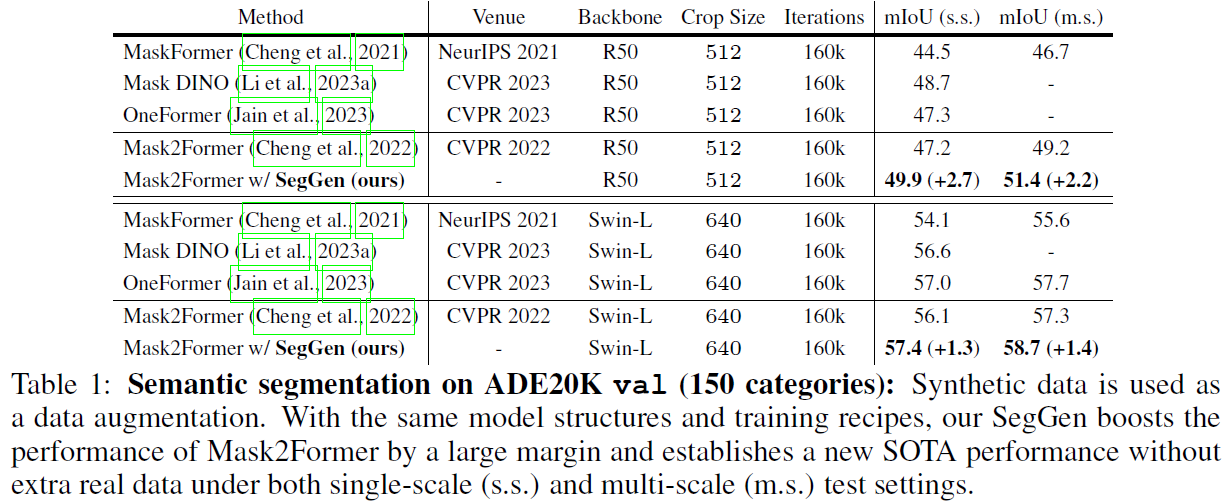
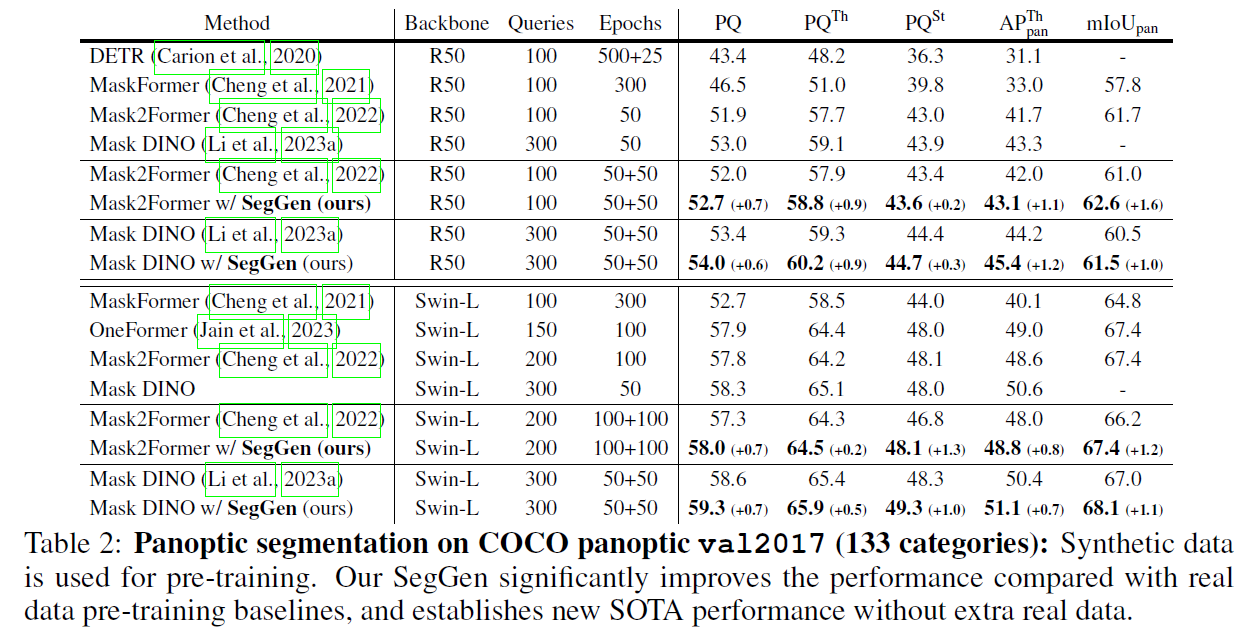
On the highly competitive ADE20K and COCO benchmarks, our data generation method markedly improves the performance of state-of-the-art segmentation models in semantic segmentation, panoptic segmentation, and instance segmentation. Notably, in terms of the ADE20K mIoU, Mask2Former R50 is largely boosted from 47.2 to 49.9 (+2.7); Mask2Former Swin-L is also significantly increased from 56.1 to 57.4 (+1.3). These promising results strongly suggest the effectiveness of our SegGen even when abundant human-annotated training data is utilized. Moreover, training with our synthetic data makes the segmentation models more robust towards unseen domains.



Generated mask-image pairs by MaskSyn. Both masks and images are synthesized by our SegGen. The synthetic masks are highly diverse.
Generated images by ImgSyn. The masks are human-annotated. The synthetic images are realistic and align well with the masks.


BibTeX
@article{ye2023seggen,
title={SegGen: Supercharging Segmentation Models with Text2Mask and Mask2Img Synthesis},
author={Ye, Hanrong and Kuen, Jason and Liu, Qing and Lin, Zhe and Price, Brian and Xu, Dan},
journal={arXiv preprint arXiv:2311.03355},
year={2023}
}